
Inevitability Weekly #4
GPU Depreciation, Nadella on AGI, CoreWeave and more

GPU Depreciation
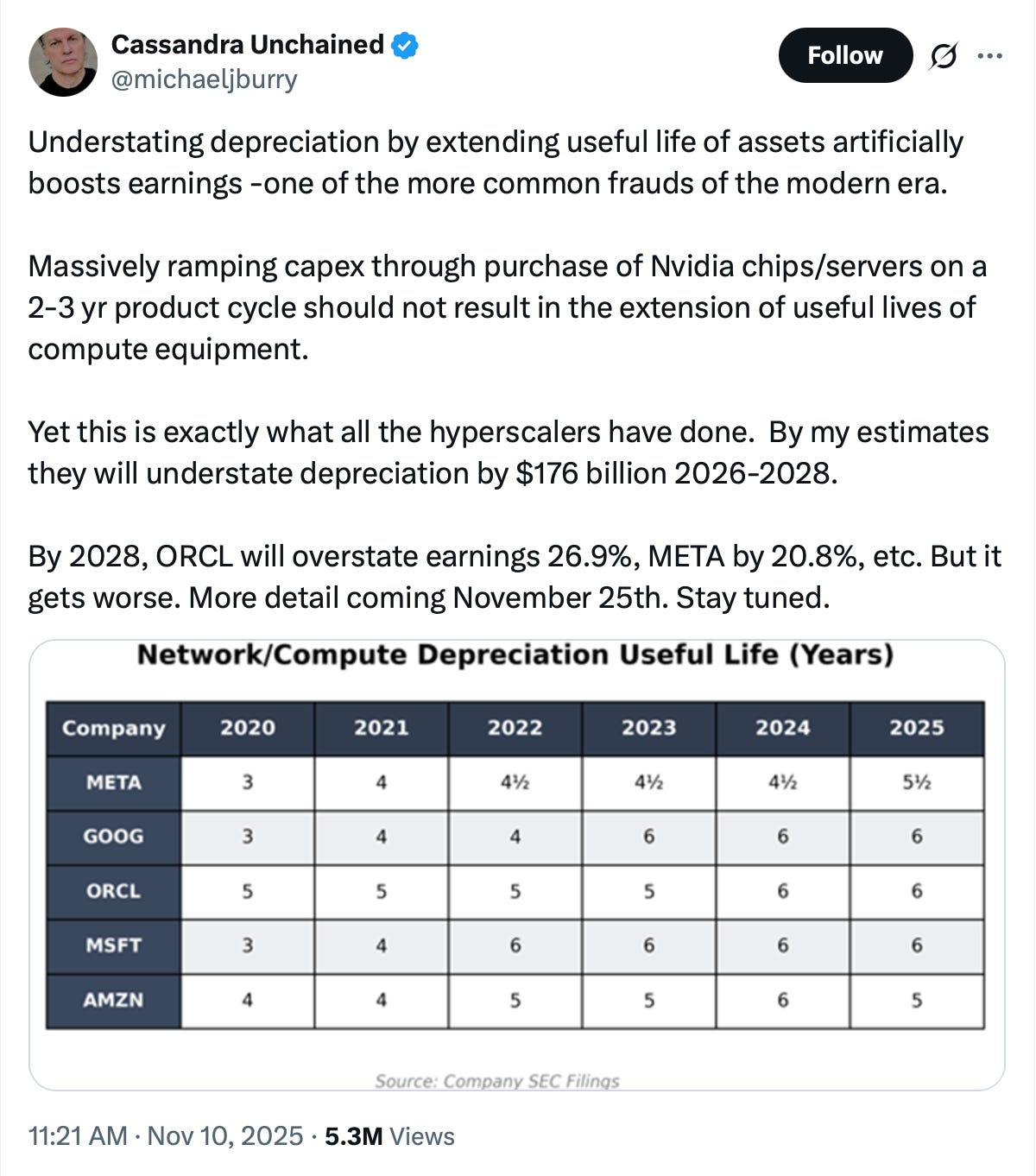
Michael Burry made waves this week with news that his hedge fund has terminated its SEC registration, possibly signaling that he is shutting it down, and for a tweet raising concerns that big tech companies may be understating depreciation expenses on GPUs by assuming longer useful lives for the machines. Burry argued that these changes will lead these companies to overstate earnings by $176B from 2026 through 2028.
SemiAnalysis highlighted the counterargument that the useful live of GPUs has actually increased.
Dr. Burry’s claim is predicated on an assumption that the NVIDIA product cycle is now 2-3 years, which is far lower than the useful life of the assets. We believe this is a fatal flaw in the argument. The new accounting, while beneficial to the companies in the short-term, is also predicated on real operational experience in datacenters.
Back in 2020, when Microsoft, Meta, and Google increased the useful life from 3 to 4 years, we were still in the year 2 BC (Before ChatGPT). Now, in present-day 3 AD (After Da Launch of ChatGPT), the increases in useful life have proved beneficial to CAPEX-hungry hyperscalers. What began changing in IT equipment in 2020 that has continued through to 2025? The answer is reliability, and incentives.
Server OEMs such as Dell, SuperMicro, HPE, Lenovo, and Cisco have long sold servers with a standard warranty between 3 to 5 years in length. The 5 year warranty is more expensive, of course, but many extended warranty options exist for 6 and 7 years. The price goes up of course, but all it takes is the vendor stocking enough spare parts to make service calls on worn out nodes. Meanwhile, networking equipment vendors such as Cisco, Arista, Aruba and Juniper have experimented with lifetime warranty on their switches. Storage vendors have offered the same - just pay a yearly support contract and they’ll keep swapping worn out drives. Think of it like a car: the high end of the market might lease and upgrade their Benz every 2 years, while others drive their 20 year older beaters for the price of gas and insurance.
QF Research also had thoughtful tweets about economic reality of H100s, rebutting Burry’s thesis.
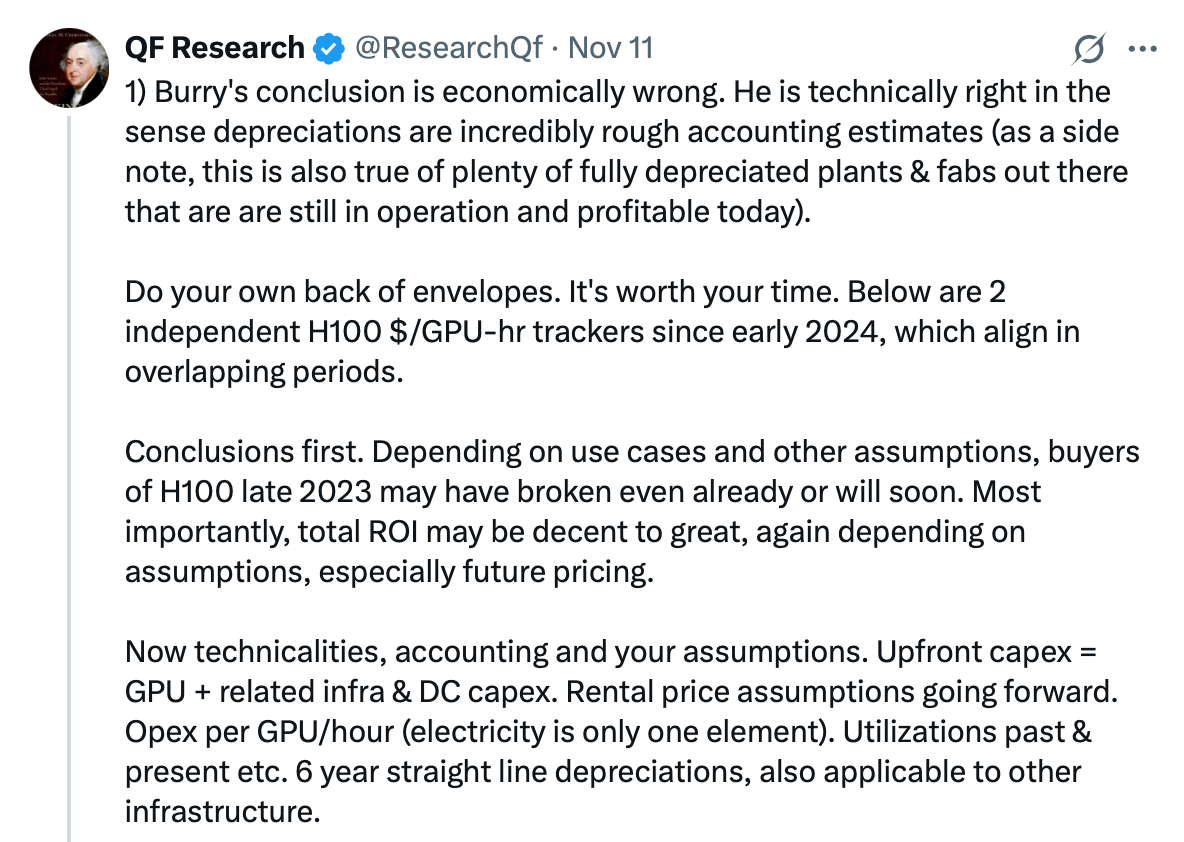
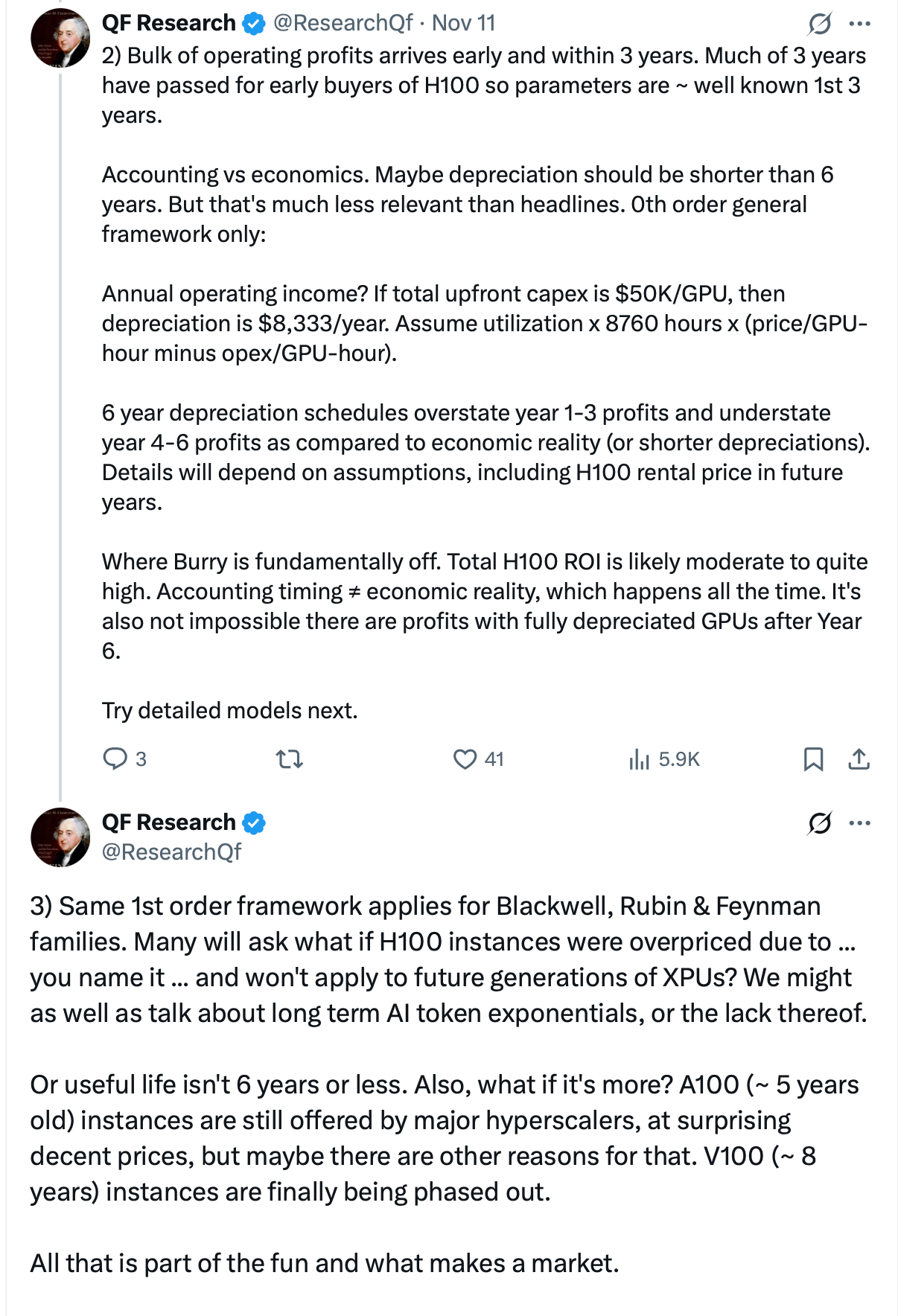
As many people highlighted, another common rebuttal is the fact that A100s are still being rented, 5 years after they were purchased, though the going profitability remains a question. I also enjoyed this tweet about the different incentives that various parties have to depreciate GPUs over different timelines.
What does this all mean?
As we highlighted in a previous piece, a few important points to note:
Big tech is in the middle of becoming an asset heavy sector. The major platforms will likely spend close to $400B of capex in 2025, and that figure is expected to keep rising through 2026 and 2027. Roughly half of that spend goes directly into servers, chips, and accelerators. These companies are no longer software businesses with light capital footprints. They are infrastructure companies building global compute utilities.
This shift matters because of the concentration of the index. The Mag7, with Broadcom substituted for Tesla, now account for roughly 36% of the S&P 500. At about 30x 2026 earnings, Wall St. expects the group to compound earnings at about a 20% CAGR over the next two years.
Burry’s point follows from that setup. If hyperscalers are assuming longer useful lives for GPUs than the economic reality justifies, then depreciation expenses are understated and earnings are overstated. Since compute hardware accounts for 50-60% of data center capex, even small changes in useful life assumptions can move earnings by tens of billions. If the group that represents over a third of the index reports lower earnings than projected, or even if the market begins to believe the earnings are overstated to a meaningful degree, it could pull down the entire market.
The counter argument is equally straightforward. The useful life of modern accelerators actually appears to be increasing. GPUs do not drop to zero after two or three years. Demand for older models like the A100 remains strong. Hyperscalers can reuse them for fine-tuning, inference, embeddings, internal workloads, and third-party cloud capacity. If the industry continues to see reasonable payback periods and positive ROIC in years 3–5, the accounting treatment becomes far less important. The real economics are determined by cash returns, not depreciation schedules, so consistent positive ROIC would matter more than whether the useful life is listed as four years or six.
From a financial perspective the most important question is the incremental ROIC that hyperscalers earn on each new dollar of AI capex. The group is on track to deploy more than $400B of AI-related capital expenditures in 2025. ROIC will appear in operating profit over time, but operating profit will be affected by the opex required to run these systems, including energy, networking, staffing, and data center operations. Depreciation can influence reported earnings, but the cash economics flow through free cash flow. This is where replacement cadence becomes relevant. If hyperscalers eventually move toward an eighteen month purchase cycle for new accelerators, the higher frequency of capex will show up immediately in free cash flow regardless of the assumed useful life. The hardware does not need to pay back before the next refresh, but it must reach economic breakeven over its productive life. The hurdle is set by the cash flows the hardware produces, not by the accounting schedule that allocates its cost.
The second factor is the relationship between replacement cadence and capacity expansion. These two variables reinforce each other. If total compute capacity can continue to scale through both hyperscalers and neocloud providers, older GPUs can remain productive even as newer hardware comes online. Many of these older accelerators will have already achieved economic payback. They can be redeployed for fine tuning, inference, embeddings, smaller models, and internal workloads. In that scenario a faster replacement cadence does not imply a shorter useful life. The newest chips expand the compute base and older chips continue to generate positive cash flow at lower margins. The constraint is not only the hardware but also the availability of power, cooling, land, and networking. If those constraints bind, capacity expansion slows and new chips begin to crowd out older ones. Economic life then compresses even if the accounting life remains long.
The third question is where value accrues within the stack. At present most value creation sits with the semiconductor supply chain, particularly NVIDIA, TSMC, and the upstream and downstream partners that support them. The hyperscalers capture value next, but only after deploying significant capital and operating large physical footprints. Consumers enjoy a large surplus because products like ChatGPT, Claude, Cursor, and Gemini offer significant capability at relatively low prices. The application layer sits in a more uncertain position. The industry has not yet demonstrated how much of the value will remain with software companies once the cost of infrastructure is considered. At this stage the hyperscalers remain price takers in accelerator supply, and the application layer has not established durable high-margin economics relative to the scale of investment being made beneath it. JP Morgan estimates that to return 10% on AI investments through 2030, there will need to be $650B in revenue in perpetuity, the equivalent of $34.72 per iPhone user.

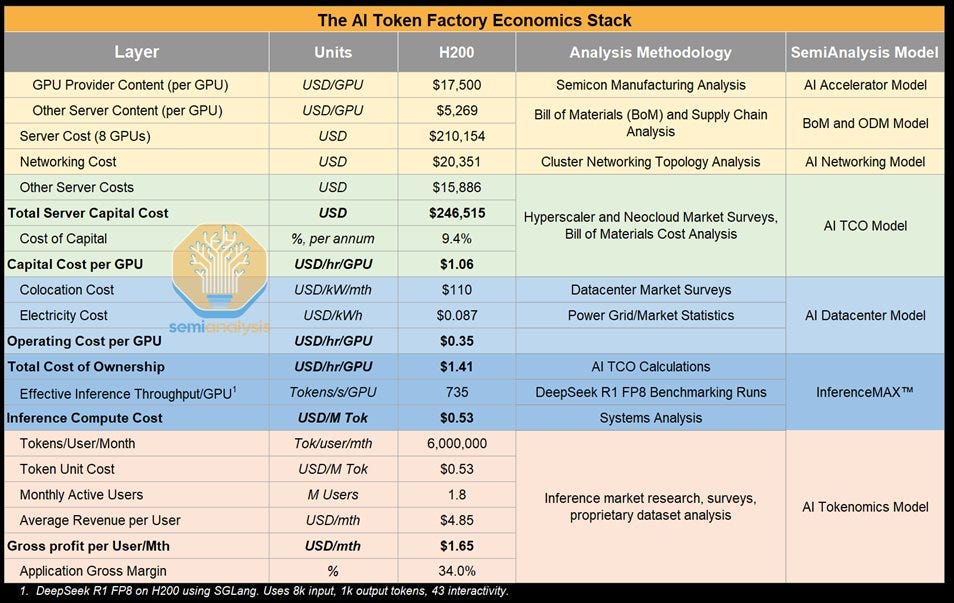
SemiAnalysis recently published a detailed cost breakdown for H200 clusters that helps frame these questions. The total capital cost per eight-GPU server is roughly $246,000, which works out to about $1.06 per GPU per hour before operating expenses. Once electricity, colocation, networking, and on-site operations are included, the total cost of ownership rises to about $1.41 per GPU per hour. These figures highlight why incremental ROIC and replacement cadence matter far more than depreciation policy. If the hardware produces enough cash flow over its productive life to cover this all-in cost, the investment case holds. If not, the underlying economics will appear in free cash flow regardless of the useful life assumptions in financial statements. A faster refresh cycle would increase the capital cost per GPU hour unless total capacity grows quickly enough to keep older hardware productive at lower margins.
This context explains why Burry’s comment stirred quite a bit of discussion. His tweet brought about a useful debate about the assumptions that sit underneath the largest capital investment cycle in modern technology. Useful life affects reported earnings, but the long term economics will be shaped by incremental ROIC, replacement cadence, capacity constraints, and the distribution of value across the stack. These variables will determine the actual return profile of AI infrastructure investment over the next decade.
Satya Nadella Interview - How Microsoft Thinks about AGI
Dwarkesh Patel and Dylan Patel sat down for a very illuminating interview with Satya Nadella where they discussed Microsoft’s new data centers, the business of AI, their partnership with OpenAI and more. I always enjoy everything that Dwarkesh and Dylan put out and this interview was both timely and informative from one of the most central figures in the AI arms race.
On the new Fairwater 2 data center:
Scott Guthrie
We’ve tried to 10x the training capacity every 18 to 24 months. So this would effectively be a 10x increase from what GPT-5 was trained with. So to put it in perspective in the number of optics, the network optics in this building is almost as much as all of Azure across all our data centers two and a half years ago.
Satya Nadella
It’s got like five million network connections.
Dwarkesh Patel
You’ve got all this bandwidth between different sites in a region and between the two regions. So is this like a big bet on scaling in the future, that you anticipate in the future that there’s going to be some huge model that will require two whole different regions to train?
Satya Nadella
The goal is to be able to aggregate these flops for a large training job and then put these things together across sites. The reality is you’ll use it for training and then you’ll use it for data gen, you’ll use it for inference in all sorts of ways. It’s not like it’s going to be used only for one workload forever.
On AGI:
Dylan Patel
When you look at all the past technological transitions—whether it be railroads or the Internet or replaceable parts, industrialization, the cloud, all of these things—each revolution has gotten much faster in the time it goes from technology discovered to ramp and pervasiveness through the economy. Many folks who have been on Dwarkesh’s podcast believe this is the final technological revolution or transition, and that this time is very, very different.
At least so far in the markets, in three years we’ve already skyrocketed to hyperscalers doing $500 billion of capex next year, which is a scale that’s unmatched to prior revolutions in terms of speed. The end state seems to be quite different. Your framing of this seems quite different from what I would call the “AI bro” who’s like, “AGI is coming.” I’d like to understand that more.
Satya Nadella
I start with the excitement that I also feel for the idea that maybe after the Industrial Revolution this is the biggest thing. I start with that premise. But at the same time, I’m a little grounded in the fact that this is still early innings. We’ve built some very useful things, we’re seeing some great properties, these scaling laws seem to be working. I’m optimistic that they’ll continue to work. Some of it does require real science breakthroughs, but it’s also a lot of engineering and what have you.
That said, I also sort of take the view that even what has been happening in the last 70 years of computing has also been a march that has helped us move. I like one of the things that Raj Reddy has as a metaphor for what AI is. He’s a Turing Award winner at CMU. He had this, even pre-AGI. He had this metaphor for AI, it should either be a guardian angel or a cognitive amplifier. I love that. It’s a simple way to think about what this is. Ultimately, what is its human utility? It is going to be a cognitive amplifier and a guardian angel. If I view it that way, I view it as a tool.
But then you can also go very mystical about it and say this is more than a tool. It does all these things, which only humans did before so far. But that has been the case with many technologies in the past. Only humans did a lot of things, and then we had tools that did them.
On where value will accrue:
Dwarkesh Patel 00:20:02
I guess the reason to focus on this question is that it’s not just about GitHub, but fundamentally about Office and all the other software that Microsoft offers. One vision you could have about how AI proceeds is that the models are going to keep being hobbled and you’ll need this direct visible observability all the time.
Another vision is that over time these models which are now doing tasks that take two minutes, in the future, they’ll be doing tasks that take 10, 30 minutes. In the future, maybe they’re doing days worth of work autonomously. Then the model companies are charging thousands of dollars maybe for access to, really, a coworker which could use any UI to communicate with their human and migrate between platforms.
If we’re getting closer to that, why aren’t the model companies that are just getting more and more profitable, the ones that are taking all the margin? Why is the place where the scaffolding happens, which becomes less and less relevant as the AI becomes more capable, going to be that important? That goes to Office as it exists now versus coworkers that are just doing knowledge work.
Satya Nadella 00:21:07
That’s a great point. Does all the value migrate just to the model? Or does it get split between the scaffolding and the model? I think that time will tell. But my fundamental point also is that the incentive structure gets clear. Let’s take information work, or take even coding. Already in fact, one of my favorite settings in GitHub Copilot is called auto, which will just optimize. In fact I buy a subscription and the auto one will start picking and optimizing for what I am asking it to do. It could even be fully autonomous. It could arbitrage the tokens available across multiple models to go get a task done.
If you take that argument, the commodity there will be models. Especially with open source models, you can pick a checkpoint and you can take a bunch of your data and you’re seeing it. I think all of us will start, whether it’s from Cursor or from Microsoft, seeing some in-house models even. And then you’ll offload most of your tasks to it.
So one argument is if you win the scaffolding—which today is dealing with all the hobbling problems or the jaggedness of these intelligence problems, which you kind of have to—if you win that, then you will vertically integrate yourself into the model just because you will have the liquidity of the data and what have you. There are enough and more checkpoints that are going to be available. That’s the other thing.
Structurally, I think there will always be an open source model that will be fairly capable in the world that you could then use, as long as you have something that you can use that with, which is data and a scaffolding. I can make the argument that if you’re a model company, you may have a winner’s curse. You may have done all the hard work, done unbelievable innovation, except it’s one copy away from that being commoditized. Then the person who has the data for grounding and context engineering, and the liquidity of data can then go take that checkpoint and train it. So I think the argument can be made both ways.
On Azure:
By the way, the other thing is that I didn’t want to get stuck with massive scale of one generation. We just saw the GB200s, the GB300s are coming. By the time I get to Vera Rubin, Vera Rubin Ultra, the data center is going to look very different because the power per rack, power per row, is going to be so different. The cooling requirements are going to be so different. That means I don’t want to just go build out a whole number of gigawatts that are only for a one-generation, one family. So I think the pacing matters, the fungibility and the location matters, the workload diversity matters, customer diversity matters and that’s what we’re building towards.
The other thing that we’ve learned a lot is that every AI workload does require not only the AI accelerator, but it requires a whole lot of other things. In fact, a lot of the margin structure for us will be in those other things. Therefore, we want to build out Azure as being fantastic for the long tail of the workloads, because that’s the hyperscale business, while knowing that we’ve got to be super competitive starting with the bare-metal for the highest end training.
On Chips and OpenAI Partnership:
Dwarkesh Patel
You mentioned how this depreciating asset, in five or six years, is 75% of the TCO of a data center. And Jensen is taking a 75% margin on that. So what all the hyperscalers are trying to do is develop their own accelerator so that they can reduce this overwhelming cost for equipment, to increase their margins.
Dylan Patel
And when you look at where they are, Google’s way ahead of everyone else. They’ve been doing it for the longest.
They’re going to make something like five to seven million chips of their own TPUs. You look at Amazon and they’re trying to make three to five million[Lifetime shipment units]. But when we look at what Microsoft is ordering of their own chips, it’s way below that number. You’ve had a program for just as long. What’s going on with your internal chips?
Satya Nadella
It’s a good question. A couple of things. One is that the thing that is the biggest competitor for any new accelerator is kind of even the previous generation of Nvidia. In a fleet, what I’m going to look at is the overall TCO. The bar I have, even for our own… By the way, I was just looking at the data for Maia 200 which looks great, except that one of the things that we learned even on the compute side… We had a lot of Intel, then we introduced AMD, and then we introduced Cobalt. That’s how we scaled it. We have good existence proof of, at least in core compute, how to build your own silicon and then manage a fleet where all three are at play in some balance.
Because by the way, even Google’s buying Nvidia, and so is Amazon. It makes sense because Nvidia is innovating and it’s the general-purpose thing. All models run on it and customer demand is there. Because if you build your own vertical thing, you better have your own model, which is either going to use it for training or inference, and you have to generate your own demand for it or subsidize the demand for it. So therefore you want to make sure you scale it appropriately.
The way we are going to do it is to have a close loop between our own MAI models and our silicon, because I feel like that’s what gives you the birthright to do your own silicon, where you literally have designed the microarchitecture with what you’re doing, and then you keep pace with your own models. In our case, the good news here is that OpenAI has a program which we have access to. So therefore to think that Microsoft is not going to have something that’s—
Dylan Patel
What level of access do you have to that?
Satya Nadella
All of it.
Dylan Patel
You just get the IP for all of that? So the only IP you don’t have is consumer hardware?
Satya Nadella
That’s it.
The entire interview is definitely worth watching. Probably the most illuminating picture into the mind of someone whose job it is to try to position his company as the winner of the AI arms race.
CoreWeave Earnings
CoreWeave remains one of the most interesting companies in the AI ecosystem because it represents a new category of infrastructure provider. It is not a hyperscaler and not a traditional cloud platform. It is a neocloud. The company was built for the AI age with a model centered on GPU utilization rather than general-purpose compute, and its scale-up has occurred entirely during the peak of the AI arms race. In March 2025 CoreWeave raised $1.5B in its IPO at a valuation of roughly $23B. The stock is up about 90% since then, valuing the company at about $37B. The company has also relied heavily on debt financing and has accumulated more than $19B of total debt plus operating leases as of Q3. In July CoreWeave closed an additional $2.6B secured facility, part of more than $25B in combined equity and debt raised in less than two years.
The Q3 results highlight both the growth and the uncertainty of the neocloud model. Revenue for the quarter reached $1.36B, up from $584M a year ago. For the first nine months of 2025, revenue totaled $3.56B compared with $1.17B in the same period of 2024. The company is scaling quickly, but the cost structure remains complex. Cost of revenue was $369M in Q3 and $944M for the year to date. Technology and infrastructure expense was $747M in Q3 and $1.98B for the first nine months. These lines include power, networking, bandwidth, operational labor, and hardware depreciation that is embedded across several categories instead of appearing as a separate line item. As a result, it is difficult to determine the true economic margin of the business from the income statement alone. CoreWeave reported an operating loss of $237M in Q3 and a net loss of $110M, which contributed to a year-to-date net loss of $715M.
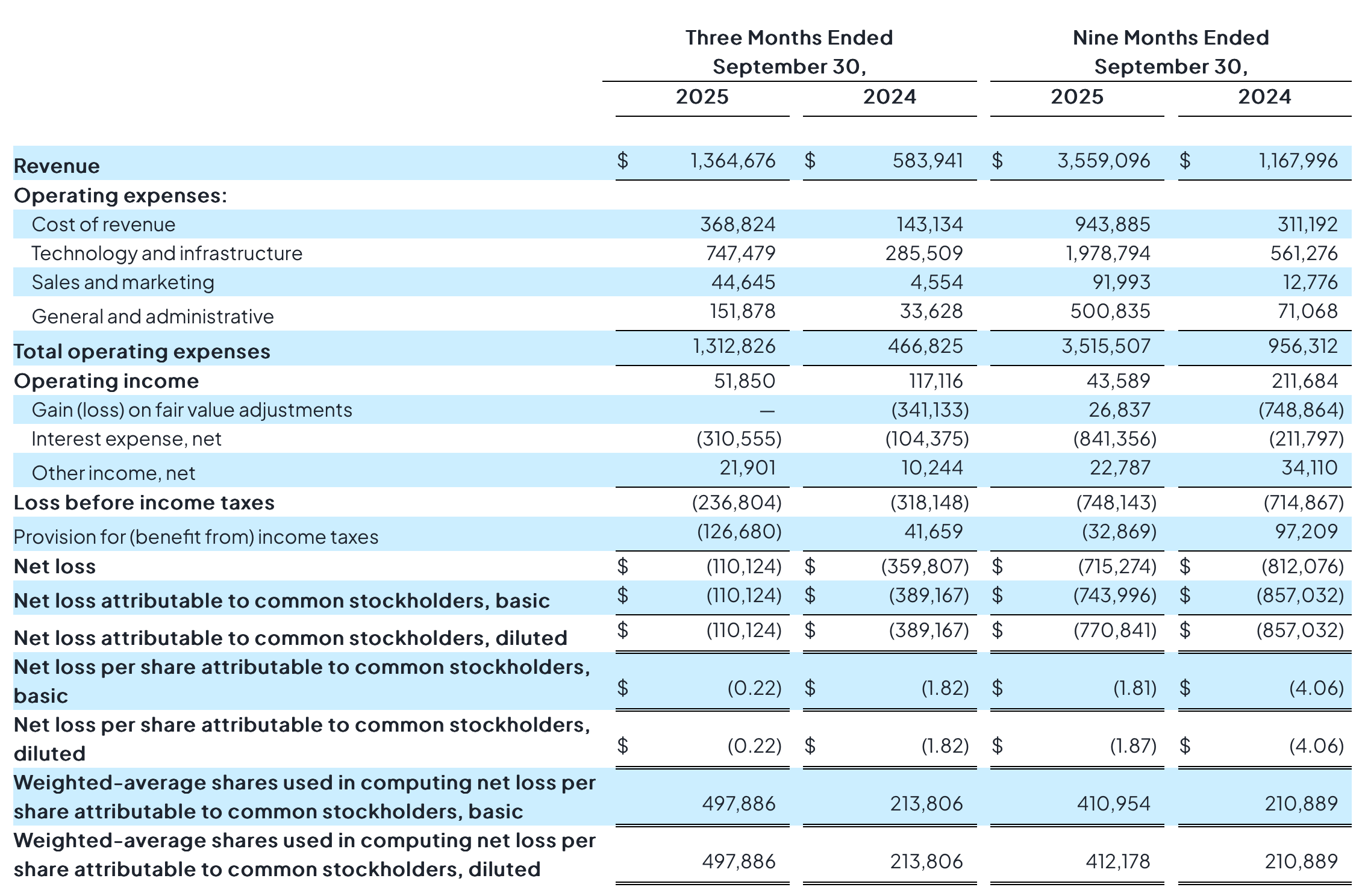
The balance sheet gives a clearer view of the scale of investment. Total assets increased from $17.83B at year-end 2024 to $32.91B at the end of Q3 2025. Property and equipment grew from $11.91B to $20.66B in the same period. The company is adding nearly $9B of hardware and data center assets in only nine months. Total liabilities also expanded to $29.03B, reflecting a growing mix of current and long-term obligations. CoreWeave’s capital structure is therefore highly leveraged, and the long-term return on these invested dollars has not yet been demonstrated.
This combination of rapid growth, heavy capital spending, and an untested margin structure makes CoreWeave an important company to monitor. It is the closest real-time example of what a pure AI infrastructure provider looks like in practice. The sustainability of the model will depend on several factors. Utilization must remain high. Replacement cycles must align with the payback period of the hardware. Capacity must grow fast enough to keep older GPUs productive at lower margins. Operating scale must eventually lead to efficiency improvements. If these conditions hold, the neocloud model could mature into a viable alternative to traditional hyperscalers. If they do not hold, the economics may ultimately favor only the largest platforms with the power, land, and balance sheet required to support multi-billion-dollar annual capex cycles.
Either way, CoreWeave offers a clear window into how AI infrastructure economics may evolve. Their earnings will be an extremely useful proxy into GPU pricing.
On their earnings call, they provided useful insights into the state of AI:
In Q3, we beat expectations, delivering revenue of $1.4 billion, up 134% year-over-year. We added over $25 billion in revenue backlog in the third quarter alone, bringing us to over $55 billion in revenue backlog to end Q3, almost double Q2 and approaching 4 times year to date. Further, CoreWeave has reached $50 billion in RPO faster than any cloud in history. These results demonstrate the deep confidence customers have in CoreWeave, the company they trust as their essential cloud for artificial intelligence.
We continue to scale aggressively even as the industry remains capacity constrained. We expanded our active power footprint by 120 megawatts sequentially to approximately 590 megawatts, while growing our contracted power capacity over 600 megawatts to 2.9 gigawatts. This leaves us well-positioned for future growth, with more than 1 gigawatt of contracted capacity available to be sold to customers that we expect to largely come online within the next 12 to 24 months.
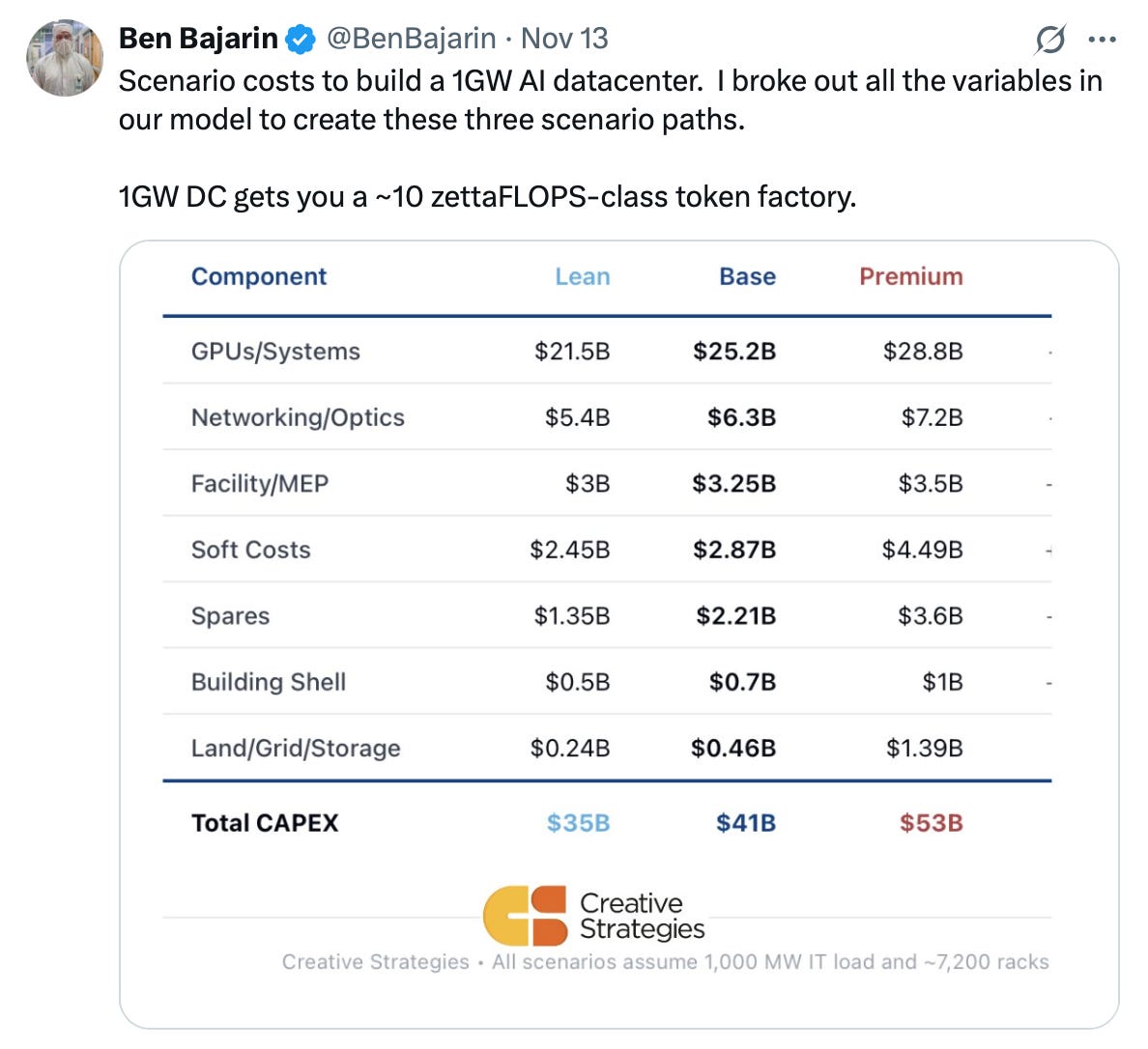
For context, I found this tweet helpful in understanding the costs involved in building a 1 GW AI data center
CoreWeave also noted their deployment of GB200 and GB300s as well as customers renewing H100 rentals within 5% of the original price:
In the third quarter, we continued to deliver many of the initial scaled deployments of the GB200s, while once again being first to market, this time with the GB300s, further highlighting our incredible track record of operational excellence.
CoreWeave’s industry leadership is unmatched. We are the only cloud provider to submit MLPerf inference result for GB300s, setting the benchmark for real-world AI performance. And just last week, SemiAnalysis once again recognized our dominance, awarding CoreWeave its highest possible distinction, its Platinum ClusterMAX ranking, for the second time ahead of more than 200 providers, including the hyperscalers and emerging neoclouds. No other cloud has achieved this once. CoreWeave has done it twice, underscoring yet again that CoreWeave stands alone at the forefront of the AI cloud.
Demand for AI cloud technology remains robust across generations of GPUs. For example, in Q3, we saw our first 10,000-plus H100 contract approaching expiration. Two quarters in advance, the customer proactively re-contracted for the infrastructure at a price within 5% of the original agreement. This is a powerful indicator of customer satisfaction, as well as the long-term utility and differentiated value of the GPUs run on CoreWeave’s platform.
CoreWeave uses a 6 year useful life for their GPU depreciation. Customers re-upping older models at close to the original price lends credibility to the idea that GPUs have a longer useful life than 2-3 years but this is also during a supply shortage, so the economics when demand and supply are more balanced and the industry is more mature remain to be seen. This is area to monitor closely and one we will be actively covering.
Also worth mentioning is that in their AI Capex Report, JP Morgan predicted $1.5T of funding for AI data centers from the high grade bond markets over the next 5 years.
High Grade capital markets will look very different. We think High Grade markets could absorb $300 billion of AI/data center related paper over the next year, and are assuming $1.5 trillion of funding from High Grade bond markets over the next five years. AI/Data center capex-related sectors already represent 14.5% of the JULI Index, which is larger than the US Banks component of the index. Mathematically, if anything like our forecast plays out, AI/Data Center related sectors could represent north of 20% of the market by 2030. Historically, lumpy issuance from select sectors is not “new” to High Grade. Recent examples like Healthcare (‘21-’24) and Telecom (‘16-’19) have been manageable and in both cases led to 15-20bp of underperformance from the impacted sector.
So there will be more debt involved in the financing of AI data centers and it remains to be seen how valuable the equity in a company with a model like CoreWeave’s will be.
Warren Buffett’s Final Shareholder Letter
Warren Buffett wrote his final letter to Berkshire’s shareholders on November 10, 2025. As always, it is filled with timeless wisdom and insights from an incredible lifetime. The collection of his shareholder letters is an amazing book and one that I would highly recommend for anyone interested in investing.
One perhaps self-serving observation. I’m happy to say I feel better about the second half of my life than the first. My advice: Don’t beat yourself up over past mistakes – learn at least a little from them and move on. It is never too late to improve. Get the right heroes and copy them. You can start with Tom Murphy; he was the best.
Remember Alfred Nobel, later of Nobel Prize fame, who – reportedly – read his own obituary that was mistakenly printed when his brother died and a newspaper got mixed up. He was horrified at what he read and realized he should change his behavior.
Don’t count on a newsroom mix-up: Decide what you would like your obituary to say and live the life to deserve it.
Greatness does not come about through accumulating great amounts of money, great amounts of publicity or great power in government. When you help someone in any of thousands of ways, you help the world. Kindness is costless but also priceless. Whether you are religious or not, it’s hard to beat The Golden Rule as a guide to behavior.
I write this as one who has been thoughtless countless times and made many mistakes but also became very lucky in learning from some wonderful friends how to behave better (still a long way from perfect, however). Keep in mind that the cleaning lady is as much a human being as the Chairman.
************
I wish all who read this a very happy Thanksgiving. Yes, even the jerks; it’s never too late tochange. Remember to thank America for maximizing your opportunities. But it is – inevitably – capricious and sometimes venal in distributing its rewards.
Looking Ahead and Roundup
This week all eyes will be on NVIDIA’s Q3 earnings and Alphabet’s rumored release of Gemini 3. It seems like the news cycle will continue to be dominated by all things AI for the foreseeable future.
This week saw Cursor raise $2.3B at a $29.3B valuation.
Anthropic announced a $50B data center investment and that it disrupted the first reported AI-orchestrated cyber espionage campaign.
Sundar Pichai posted a cryptic tweet that seemed to imply Gemini 3 will be released this week.
Bill Ackman offered some dating advice and quickly sparked a new meme.
Wall St. expects $54B in revenue from NVIDIA this week, with $48B coming from data centers as production ramps up for their Blackwell systems.
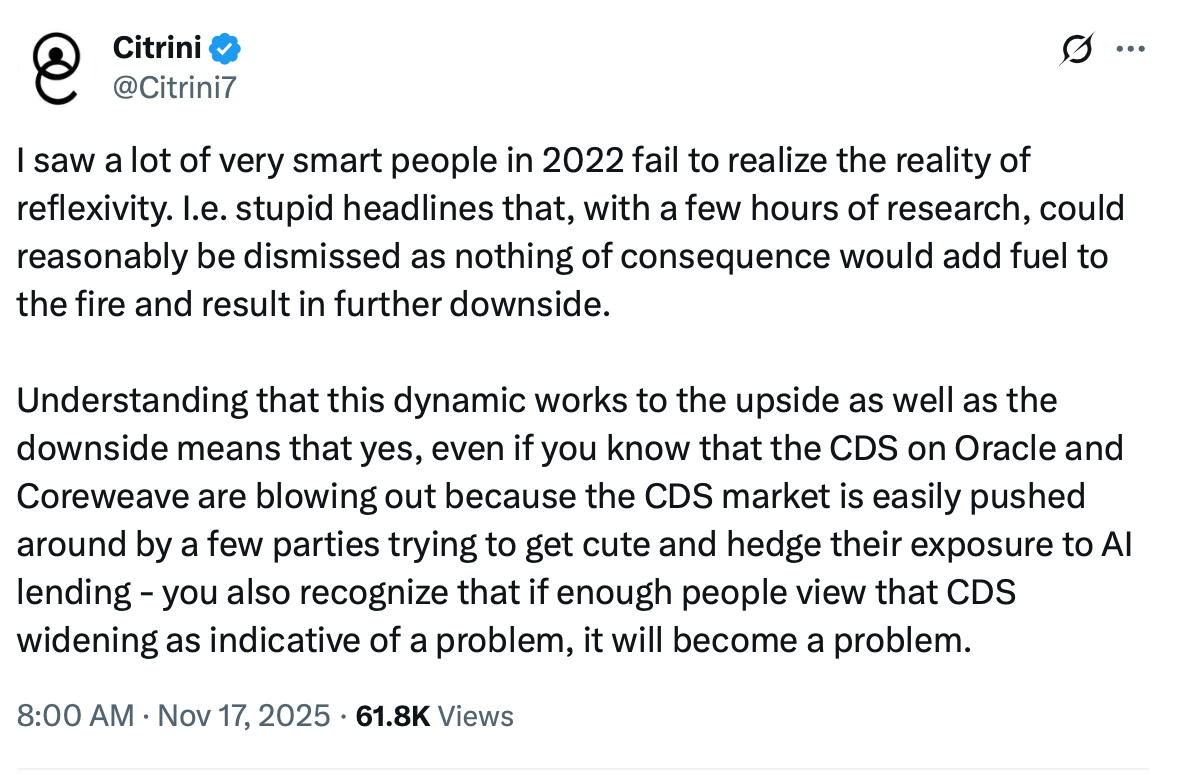
Citrini had a great tweet about reflexivity as it pertains to CDS spreads widening for CoreWeave and Oracle.
As always, thanks for reading and we’ll see you next week.
may i thank you for explaining the gpu depreciation debate
You think you’ll keep doing these?